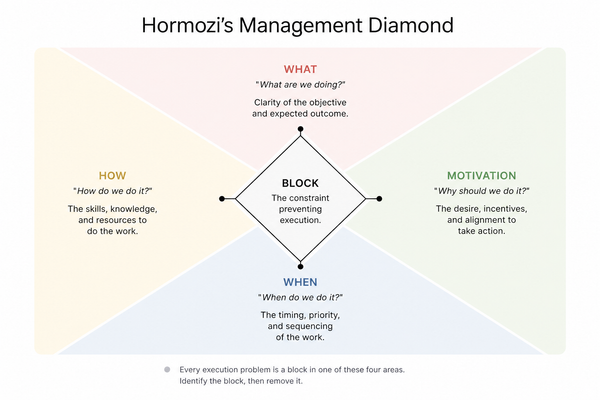
What Amazon Taught Me About Building on OpenAI
Search Amazon for USB-C cables. The first several results are Amazon Basics.

Search Amazon for USB-C cables. The first several results are Amazon Basics.
Below them, scrolling for a minute, are the third-party listings that taught Amazon what to stock: same braided nylon, same right-angle connectors, same 100W rating, slightly higher prices, two thousand reviews each. Amazon used to be the storefront where those sellers built their businesses. Now Amazon is the storefront and the competing brand and the algorithm that decides whose listing you see first. The same thing has happened with batteries, HDMI cables, USB hubs, microfiber cloths, and some kitchen stuff I use every morning. After watching a Jason Calacanis clip from last week about OpenAI, I think the same pattern is about to play out at the AI layer.
The reason I care is not because I think OpenAI is uniquely villainous, or because every company building on top of a model API is doomed. I care because this is now a buyer-side risk. If you are choosing AI tools for a company, you are no longer just evaluating whether the product works. You are evaluating whether the category survives contact with the platform it depends on.
The model provider is not just infrastructure. It can see demand forming across its ecosystem, identify the highest-value workflows, and decide which ones to absorb. That changes how I think about contract length, integration depth, data portability, and whether a vendor’s moat is real or just early distribution.
What Amazon actually did
Amazon didn’t guess what to put in its own product line. The marketplace told them. Every third-party seller who got traction handed Amazon a free piece of demand research: this category sells, this price point converts, these reviews complain about these specific things. Amazon picked the categories with the most volume and the least defensibility, commodity electronics and basic home goods and anything where the brand name didn’t matter much, and shipped their own version. The seller’s reward for finding product-market fit on Amazon was watching Amazon ship a near-identical product, list it above theirs in search, and price it ten percent below. The third-party listings still exist; they just stopped mattering.
OpenAI is running the same play
Calacanis’s argument is short. OpenAI publishes the list of customers using the most tokens, and that list is the closest thing in tech to Amazon’s internal sales data: it tells OpenAI which categories of work, at scale, people are paying real money to do. Cursor for code, Suno for music, Duolingo for language learning, Indeed for hiring, Code Rabbit for review, Harvey for legal. Each one is a category that has been validated, in production, by someone else’s customers and someone else’s engineering work.
Sam Altman has committed to spending $1.4 trillion on infrastructure. Token revenue alone can’t sustain that. Per-call prices drop roughly ninety percent a year, and the only revenue stream that scales fast enough to fill the gap sits at the application layer. OpenAI has shipped a browser, a video product to compete with TikTok, an agentic security product, and is reportedly building a device. The pattern matches Microsoft’s run at Lotus and WordPerfect in the nineties and Facebook’s run at Zynga a decade ago. Both times the platform let third parties prove the demand, then absorbed the category. Anthropic, by contrast, has been explicit that it doesn’t want to compete with its API customers. That’s a deliberate position from the company, and one of the few things that distinguishes the model providers from each other right now.
Why this matters when you’re the buyer
If you sit on the buyer side of this, picking tools that your team or your firm will depend on for a few years, the Amazon Basics question is now part of vendor selection. For each vendor on your shortlist: what part of their roadmap is on OpenAI’s leaderboard? If you’re rolling Harvey out to your legal team, you’re also evaluating whether OpenAI ships a comparable legal-research product in eighteen months. If you’re standardizing on Cursor for your engineering org, you’re evaluating whether OpenAI’s own code product becomes the default. The answer doesn’t have to be no, but it changes the math: shorter contracts, more skepticism about deep custom integrations, more weight on whether you can swap the underlying model out without rewriting your workflow. The tools that survive this cycle will be the ones whose value isn’t reproducible from a model API and a few months of engineering.
Why this matters when you’re the builder
If you ship a product on top of a model API, you are a third-party seller on someone else’s marketplace. The defenses available to you are the same ones that worked for the small subset of Amazon sellers who didn’t get crushed: own the customer relationship directly so the platform can’t reach them through you, hold proprietary data the platform can’t see, pick categories the platform won’t bother with (regulated workflows, niche verticals, anything that requires on-the-ground sales and integration work), or build on a vendor that has chosen not to compete with you. None of these are easy, and most of them require choosing the harder market on purpose. Most thin wrappers will lose; the ones that don’t will look, from outside, like they made things harder for themselves than they needed to.
What to ask before betting
The questions worth being able to answer before betting on a vendor are different on each side.
For the buyer: if a vendor’s category shows up in a ChatGPT product update next year, what’s the contingency, and does the contract length match how confident the answer is?
For the builder: what part of what you ship can the model provider not reproduce from their own server logs, and if the answer is “not much,” is that a position you can defend, or a runway you’re hoping outlasts them?